


LLMs have ushered in a brand new period of general-purpose imaginative and prescient techniques, showcasing their prowess in processing visible inputs. This integration has led to the unification of various vision-language duties via instruction tuning, marking a big stride within the convergence of pure language understanding and visible notion.
Researchers from Johns Hopkins College, Meta, College of Toronto, and the College of Central Florida suggest VistaLLM, a strong visible system tackling coarse and fine-grained vision-language duties throughout single and a number of enter photos via a unified framework. Using an instruction-guided picture tokenizer and a gradient-aware adaptive sampling approach extracts compressed and refined options, representing binary segmentation masks as sequences.
Multimodal massive language fashions (MLLMs), initially designed for image-level duties like visible query answering and captioning, have advanced to deal with region-specific imaginative and prescient and language challenges. Current developments, exemplified by fashions like KOSMOS-2, VisionLLM, Shikra, GPT4RoI, and Picture Encoder Instruction-Guided Picture Tokenizer, showcase the mixing of region-based referring and grounding duties inside general-purpose imaginative and prescient techniques. This progress signifies a shift in direction of enhanced region-level vision-language reasoning, marking a considerable leap within the capabilities of MLLMs for advanced multimodal duties.
Giant language fashions excel in pure language processing, however designing general-purpose imaginative and prescient fashions for zero-shot options to various imaginative and prescient issues proves difficult. Current fashions have to be improved in integrating diverse input-output codecs and representing visible options successfully. VistaLLM, a mannequin, addresses coarse- and fine-grained vision-language duties for single and a number of enter photos utilizing a unified framework.
VistaLLM is a sophisticated visible system for processing photos from single or a number of sources utilizing a unified framework. It makes use of an instruction-guided picture tokenizer to extract refined options and a gradient-aware adaptive sampling approach for representing binary segmentation masks as sequences. The research additionally highlights the compatibility of EVA-CLIP with the instruction-guided picture tokenizer module within the last mannequin.
VistaLLM persistently outperforms robust baselines in a broad spectrum of imaginative and prescient and vision-language duties. It surpasses the general-purpose state-of-the-art on VQAv2 COCO Captioning by 2.3 factors and achieves a considerable 10.9 CIDEr factors achieve over the very best baseline. Picture captioning matches fine-tuned specialist fashions, showcasing the language era capabilities of LLMs. In single-image grounding duties like REC and RES, VistaLLM additionally outperforms current baselines and matches specialist fashions in RES. It units new state-of-the-art on various research like PQA BQA, VCR Novel Duties, CoSeg, and NLVR, demonstrating sturdy comprehension and efficiency throughout numerous vision-language challenges.
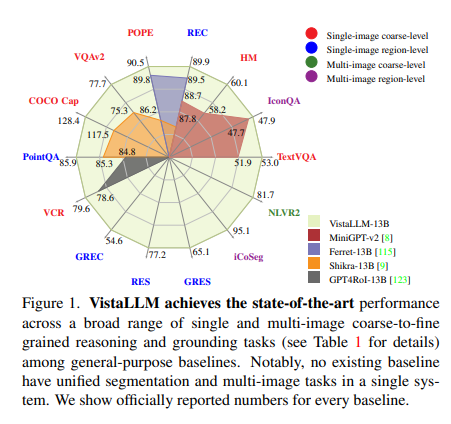
In conclusion, the research might be introduced in abstract within the following factors:
- VistaLLM is a imaginative and prescient mannequin that may deal with coarse- and fine-grained reasoning and grounding duties in single or multiple-input photos.
- It converts features right into a sequence-to-sequence format and makes use of an instruction-guided picture tokenizer for refined options.
- The researchers have launched a gradient-aware adaptive contour sampling scheme to enhance sequence-to-sequence segmentation.
- They’ve created a big instruction-tuning dataset known as CoinIt and launched AttCoSeg to deal with the dearth of multi-image grounding datasets.
- Intensive experiments have proven that VistaLLM persistently outperforms different fashions throughout various imaginative and prescient and vision-language duties.
Try the Paper and Challenge. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to affix our 34k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
For those who like our work, you’ll love our e-newsletter..
Hi there, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with expertise and wish to create new merchandise that make a distinction.