


Massive language fashions (LLMs) have emerged as highly effective instruments able to performing duties with exceptional effectivity and accuracy. These fashions have demonstrated their prowess in producing code, translating programming languages, writing unit checks, and detecting and fixing bugs. Improvements like CodeLlama, ChatGPT, and Codex have considerably improved the coding expertise by excelling in numerous code manipulation duties. Some fashions, corresponding to AlphaCode, are even pretrained on aggressive programming duties, enabling them to optimize code on the supply stage throughout a number of languages.
The problem on the coronary heart of using LLMs for duties corresponding to code era lies of their potential to supply numerous and high-quality outputs. Conventional sampling strategies, whereas helpful, typically must catch up in producing a variety of viable options. This limitation turns into notably evident in code era, the place the power to discover completely different implementation concepts can considerably improve the event course of. The issue intensifies with strategies like temperature-based sampling, which, regardless of rising output range, require in depth computation to search out the optimum setting.
Present approaches to enhancing the range and high quality of outputs from LLMs embody stochastic strategies and beam search strategies. Stochastic strategies introduce randomness within the choice course of to extend output selection, with methods like Prime-k Sampling and Nucleus Sampling specializing in probably the most possible tokens to keep up range. In the meantime, beam search strategies, corresponding to Various Beam Search and Determinantal Beam Search, manipulate enlargement mechanisms to discover completely different paths and guarantee a broader vary of generated outputs. These strategies intention to sort out the restrictions of conventional sampling by offering mechanisms that may produce extra numerous and high-quality outcomes, albeit with various levels of success and inherent challenges.
The analysis introduces Precedence Sampling, a novel technique developed by a staff from Rice College and Meta AI. This method is designed to reinforce the efficiency of LLMs in producing numerous and high-quality outputs, notably in code era and optimization. Precedence Sampling affords a deterministic method that ensures the manufacturing of distinctive samples, systematically expands the search tree based mostly on mannequin confidence, and incorporates common expression help for managed and structured exploration.
Precedence Sampling operates by increasing the unexpanded token with the best likelihood in an augmented search tree, guaranteeing that every new pattern is exclusive and ordered by the mannequin’s confidence. This method addresses the widespread concern of duplicate or irrelevant outputs present in conventional sampling strategies, offering a extra environment friendly and efficient technique of producing numerous options. Common expression help permits for extra managed exploration, enabling the era of outputs that adhere to particular patterns or constraints.
The efficiency of Precedence Sampling has been rigorously evaluated, notably within the context of LLVM pass-ordering duties. The tactic demonstrated a exceptional potential to spice up the efficiency of the unique mannequin, attaining vital enhancements over default optimization strategies. This success underscores the potential of Precedence Sampling to entry and leverage the huge data saved inside LLMs via strategic enlargement of the search tree. The outcomes spotlight the tactic’s effectiveness in producing numerous and high-quality outputs and its potential to outperform current autotuners for coaching label era.
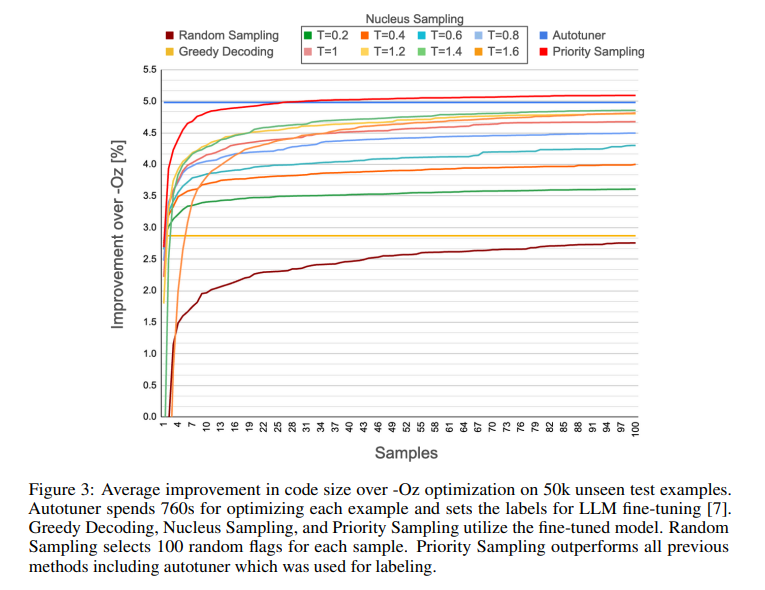
In conclusion, precedence Sampling represents a big leap ahead in using giant language fashions for code era and optimization duties. By addressing the restrictions of conventional sampling strategies, this analysis affords a extra environment friendly and efficient method to producing numerous and high-quality outputs. The tactic’s deterministic nature, coupled with its help for normal expression-based era, offers a managed and structured exploration course of that may considerably improve the capabilities of LLMs.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to affix our Telegram Channel
You may additionally like our FREE AI Programs….
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.