


Machine studying, significantly deep neural networks, focuses on creating fashions that precisely predict outcomes and quantify the uncertainty related to these predictions. This twin focus is particularly essential in high-stakes purposes equivalent to healthcare, medical imaging, and autonomous driving, the place choices primarily based on mannequin outputs can have profound implications. Correct uncertainty estimation helps assess the chance related to using a mannequin’s predictions, figuring out when to belief a mannequin’s resolution and when to override it, which is essential for secure deployment in real-world situations.
This analysis addresses the first challenge of making certain mannequin reliability and correct calibration underneath distribution shifts. Conventional strategies for uncertainty estimation in machine studying fashions typically depend on Bayesian ideas, which contain defining a previous distribution and sampling from a posterior distribution. Nonetheless, these strategies encounter vital challenges in trendy deep studying as a result of issue in specifying acceptable priors and the scalability points inherent in Bayesian approaches. These limitations hinder the sensible utility of Bayesian strategies in large-scale deep-learning fashions.
Present approaches to uncertainty estimation embody numerous Bayesian strategies and the Minimal Description Size (MDL) precept. Though theoretically sound, Bayesian strategies require intensive computational sources and face challenges defining appropriate priors for advanced fashions. The MDL precept affords another by minimizing the mixed codelength of fashions and noticed information, thereby avoiding the necessity for express priors. Nonetheless, the sensible implementation of MDL, significantly via the predictive normalized most probability (pNML) distribution, is computationally intensive. Calculating the pNML distribution entails optimizing a hindsight-optimal mannequin for every attainable label, which is infeasible for large-scale neural networks.
The Massachusetts Institute of Expertise, College of Toronto, and Vector Institute for Synthetic Intelligence analysis crew launched IF-COMP, a scalable and environment friendly approximation of the pNML distribution. This methodology leverages a temperature-scaled Boltzmann affect operate to linearize the mannequin, producing well-calibrated predictions and measuring complexity in labeled and unlabeled settings. The IF-COMP methodology regularizes the mannequin’s response to extra information factors by making use of a proximal goal that penalizes motion in operate and weight house. IF-COMP softens the native curvature by incorporating temperature scaling, permitting the mannequin to accommodate low-probability labels higher.
The IF-COMP methodology first defines a temperature-scaled proximal Bregman goal to scale back mannequin overconfidence. This entails linearizing the mannequin with a Boltzmann affect operate, approximating the hindsight-optimal output distribution. The ensuing complexity measure and related pNML code allow the technology of calibrated output distributions and the estimation of stochastic complexity for each labeled and unlabeled information factors. Experimental validation of IF-COMP was carried out on duties equivalent to uncertainty calibration, mislabel detection, and out-of-distribution (OOD) detection. In these duties, IF-COMP constantly matched or outperformed sturdy baseline strategies.
Efficiency analysis of IF-COMP revealed vital enhancements over present strategies. For instance, in uncertainty calibration on CIFAR-10 and CIFAR-100 datasets, IF-COMP achieved decrease anticipated calibration error (ECE) throughout numerous corruption ranges than Bayesian and different NML-based strategies. Particularly, IF-COMP supplied a 7-15 occasions speedup in computational effectivity in comparison with ACNML. In mislabel detection, IF-COMP demonstrated sturdy efficiency with an space underneath the receiver working attribute curve (AUROC) of 96.86 for human noise on CIFAR-10 and 95.21 for uneven noise on CIFAR-100, outperforming strategies like Trac-IN, EL2N, and GraNd.
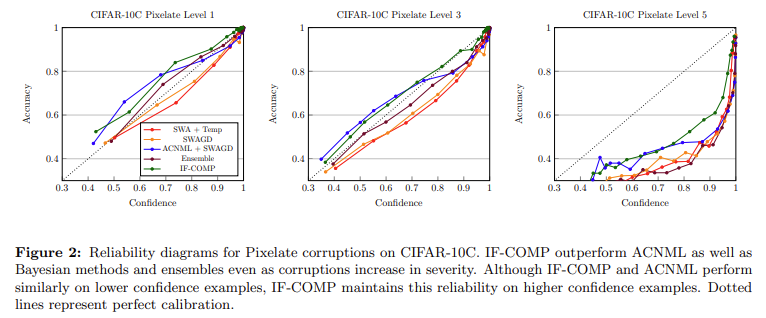
IF-COMP achieved state-of-the-art ends in OOD detection duties. On the MNIST dataset, IF-COMP attained an AUROC of 99.97 for far-OOD datasets, considerably outperforming all 20 baseline strategies within the OpenOOD benchmark. On CIFAR-10, IF-COMP set a brand new normal with an AUROC of 95.63 for far-OOD datasets. These outcomes underscore IF-COMP’s effectiveness in offering calibrated uncertainty estimates and detecting mislabeled or OOD information.

In conclusion, the IF-COMP methodology considerably advances uncertainty estimation for deep neural networks. By effectively approximating the pNML distribution utilizing a temperature-scaled Boltzmann affect operate, IF-COMP addresses the computational challenges of conventional Bayesian and MDL approaches. The tactic’s sturdy efficiency throughout numerous duties, together with uncertainty calibration, mislabel detection, and OOD detection, highlights its potential for enhancing the reliability and security of machine studying fashions in real-world purposes. The analysis demonstrates that MDL-based approaches, when carried out successfully, can present strong and scalable options for uncertainty estimation in deep studying.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.