


Latest research have highlighted the efficacy of Selective State House Layers, often known as Mamba fashions, throughout varied domains, equivalent to language and picture processing, medical imaging, and information evaluation. These fashions supply linear complexity throughout coaching and quick inference, considerably boosting throughput and enabling environment friendly dealing with of long-range dependencies. Nevertheless, understanding their information-flow dynamics, studying mechanisms, and interoperability stays difficult, limiting their applicability in delicate domains requiring explainability.
A number of strategies have been developed to reinforce explainability in deep neural networks, notably in NLP, pc imaginative and prescient, and attention-based fashions. Examples embrace AttentionRollout, which analyzes inter-layer pairwise consideration paths, combining LRP scores with consideration gradients for class-specific relevance, and treating output token representations as states in a Markov chain improved attributions by treating sure operators as constants.
Tel Aviv College researchers have proposed reformulating Mamba computation to handle gaps in understanding utilizing a data-control linear operator. This could reveal hidden consideration matrices throughout the Mamba layer, enabling the applying of interpretability strategies from transformer realms to Mamba fashions. The tactic sheds gentle on the basic nature of Mamba fashions, supplies interpretability instruments primarily based on hidden consideration matrices, and compares Mamba fashions to transformers.
The researchers reformulate selective state-space (S6) layers as self-attention, permitting the extraction of consideration matrices. These matrices are leveraged to develop class-agnostic and class-specific instruments for explainable AI of Mamba fashions. The formulation entails changing S6 layers into data-controlled linear operators and simplifying the hidden matrices for interpretation. Class-agnostic instruments make use of Consideration Rollout, whereas class-specific instruments adapt transformer attribution, modifying it to make the most of gradients of the S6 mixer and gating mechanisms for higher relevance maps.
Visualizations of consideration matrices present similarities between Mamba and Transformer fashions in capturing dependencies. Explainability metrics point out that Mamba fashions carry out comparably to Transformers in perturbation assessments, demonstrating sensitivity to perturbations. Mamba achieves larger pixel accuracy and imply Intersection over Union in segmentation assessments, however Transformer-Attribution constantly outperforms Mamba-Attribution. Additional changes to Mamba-based attribution strategies could improve efficiency.
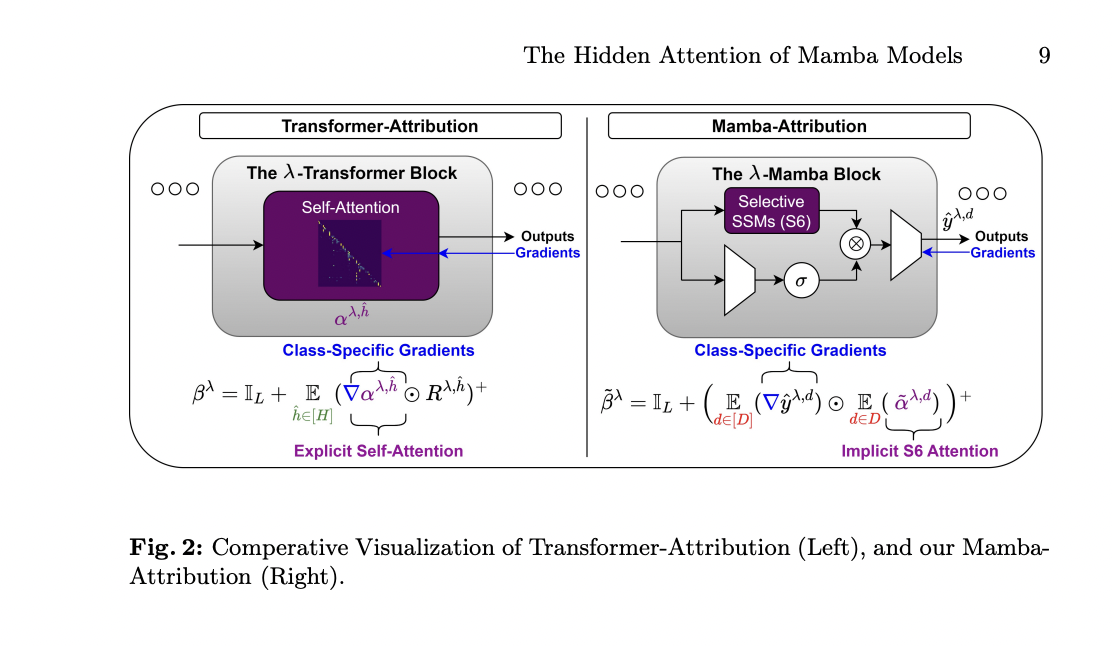
In conclusion, the researchers from Tel Aviv College have proposed a piece that establishes a direct hyperlink between Mamba and self-attention layers, revealing that Mamba layers might be reformulated as an implicit type of causal self-attention. This perception permits the event of explainability strategies for Mamba fashions, enhancing understanding of their internal representations. These contributions present worthwhile instruments for evaluating Mamba mannequin efficiency, equity, and robustness and open avenues for weakly supervised downstream duties.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
You may additionally like our FREE AI Programs….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible functions. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.