


Massive language fashions (LLMs) comparable to GPT-4 and Llama are on the forefront of pure language processing, enabling varied functions from automated chatbots to superior textual content evaluation. Nonetheless, the deployment of those fashions is hindered by excessive prices and the need to fine-tune quite a few system settings to attain optimum efficiency.
The deployment of LLMs entails a posh choice course of amongst varied system configurations, comparable to mannequin parallelization, batching methods, and scheduling insurance policies. Historically, this optimization requires in depth and dear experimentation. For example, discovering probably the most environment friendly deployment configuration for the LLaMA2-70B mannequin might eat over 42,000 GPU hours, amounting to roughly $218,000 in bills.
A gaggle of researchers from Georgia Institute of Expertise, Microsoft Analysis India, has developed Vidur, a simulation framework particularly designed for LLM inference. Vidur employs a mixture of experimental knowledge and predictive modeling to simulate the efficiency of LLMs beneath totally different configurations. This simulation permits for assessing key efficiency metrics like latency and throughput with out pricey and time-consuming bodily trials.
A pivotal part of Vidur is its configuration search device, Vidur-Search, which automates the exploration of deployment configurations. This device effectively pinpoints probably the most cost-effective settings that meet predefined efficiency standards. For instance, Vidur-Search decided an optimum setup for the LLaMA2-70B mannequin on a CPU platform in only one hour, a activity usually requiring in depth GPU assets.
Vidur’s capabilities prolong to evaluating varied LLMs throughout totally different {hardware} setups and cluster configurations, sustaining a prediction accuracy price of lower than 9% error for inference latency. The framework additionally introduces Vidur-Bench, a benchmark suite that facilitates complete efficiency evaluations utilizing various workload patterns and system configurations.
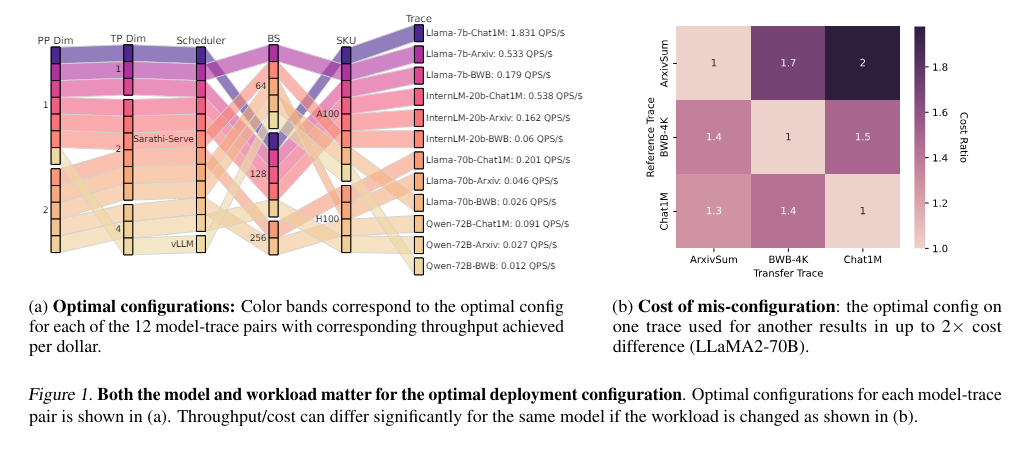
In observe, Vidur has demonstrated substantial price reductions in LLM deployment. Utilizing Vidur-Search in simulation environments has dramatically lower down potential prices. What would have amounted to over $200,000 in real-world bills will be simulated for a fraction of the price. This effectivity is achieved with out sacrificing the accuracy or relevance of the outcomes, guaranteeing that efficiency optimizations are each sensible and efficient.

In conclusion, the Vidur simulation framework addresses the excessive prices and complexity of deploying massive language fashions by introducing an progressive methodology combining experimental profiling with predictive modeling. This strategy allows correct simulation of LLM efficiency throughout varied configurations, considerably lowering the necessity for costly and time-consuming bodily testing. Vidur’s efficacy is underscored by its capability to fine-tune deployment configurations, reaching lower than 9% error in latency predictions and drastically chopping down on GPU hours and associated prices, making it a pivotal device for streamlining LLM deployment in sensible, cost-effective methods.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.