
?")

Within the quickly evolving world of deep studying and pc imaginative and prescient, some architectures have left an enduring influence on account of their simplicity, effectiveness, and scalability. One such landmark mannequin is VGG, developed by the Visible Geometry Group on the College of Oxford.
If you happen to’re exploring convolutional neural networks (CNNs) or looking for a robust, well-established mannequin for picture recognition, understanding VGG is a should.
On this article, we’ll cowl what VGG is, its structure, benefits, disadvantages, real-world purposes, and often requested inquiries to showcase a whole image of why VGG continues to affect deep studying as we speak.
What’s Visible Geometry Group (VGG)?
VGG, quick for Visible Geometry Group, is a extensively used deep convolutional neural networks (CNNs) structure recognized for its a number of layers. The time period “deep” signifies the big variety of layers within the community, with VGG-16 and VGG-19 comprising 16 and 19 convolutional layers, respectively.
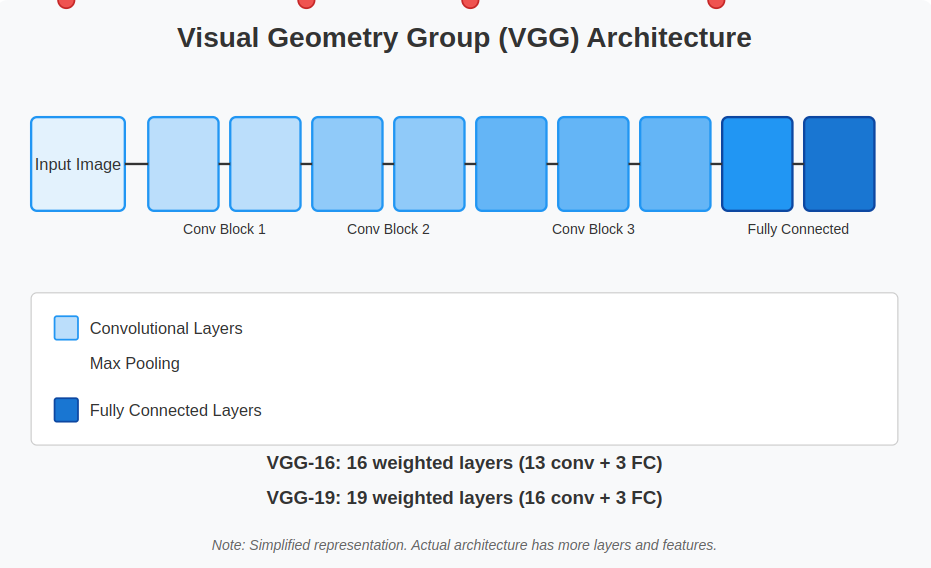
VGG has performed a major position in advancing object recognition fashions and has outperformed many baseline fashions throughout varied duties and datasets, together with ImageNet.
Regardless of being developed years in the past, it stays one of the extensively used architectures for picture recognition on account of its effectiveness and structured design.
Why is VGG Necessary?
VGG’s success lies in its simplicity and effectiveness:
- It makes use of solely 3×3 convolutional layers stacked on prime of one another.
- It will increase depth to enhance accuracy.
- It’s extremely transferable to totally different imaginative and prescient duties like object detection, segmentation, and magnificence switch.
Despite the fact that newer architectures like ResNet and EfficientNet have surpassed VGG in effectivity, VGG stays a foundational mannequin in pc imaginative and prescient training and follow.
Prompt: Free Deep Studying Programs
VGG Structure Defined in Element
The VGG structure stands out on account of its elegant simplicity and systematic design. The principle idea focuses on using small convolutional filters (3×3) and layering them extra deeply to seize intricate options from photographs.
Let’s analyze the construction step-by-step:
1. Enter Layer:
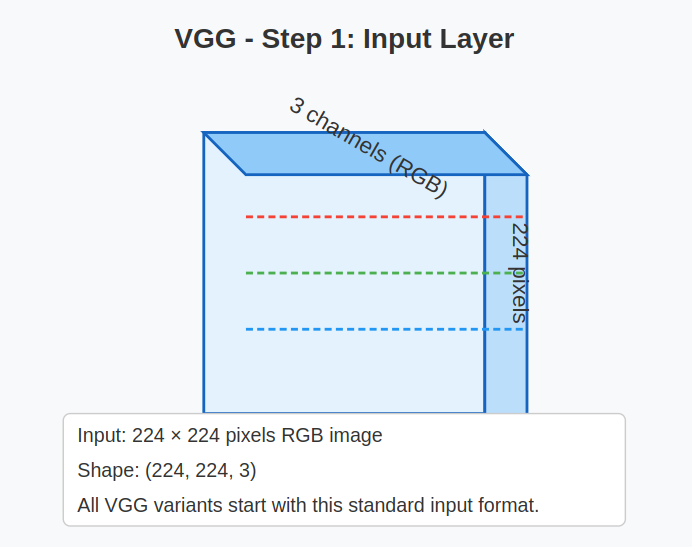
- Enter measurement: VGG is designed to soak up fixed-size photographs of 224 x 224 pixels with 3 colour channels (RGB).
Instance: Enter form = (224, 224, 3)
2. Convolutional Layers:

- VGG makes use of a number of convolutional layers with:
- Filter measurement: 3×3
- Stride: 1
- Padding: ‘Identical’ (to protect spatial decision)
- The three×3 kernel captures fine-grained particulars whereas stacking layers will increase the receptive subject.
- Depth will increase progressively throughout the community by including extra filters (ranging from 64 and going as much as 512).
Why stack a number of 3×3 convolutions?
Stacking two 3×3 convolutions has the identical efficient receptive subject as a single 5×5 convolution however with fewer parameters and extra non-linearity.
3. Activation Perform:

- After each convolutional layer, VGG applies a ReLU (Rectified Linear Unit) activation.
- This introduces non-linearity, serving to the community be taught complicated patterns effectively.
Method: ReLU(x) = max(0, x)
4. Pooling Layers:
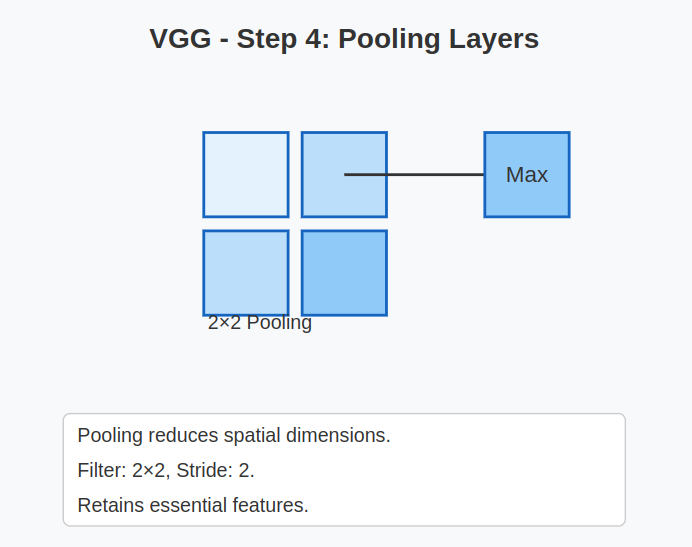
- After each few convolutional blocks, VGG makes use of a Max Pooling layer.
- Filter measurement: 2×2
- Stride: 2
- Objective: To cut back the spatial dimensions (peak and width) whereas holding essentially the most important options.
- This helps scale back computation and controls overfitting.
5. Totally Linked (Dense) Layers:
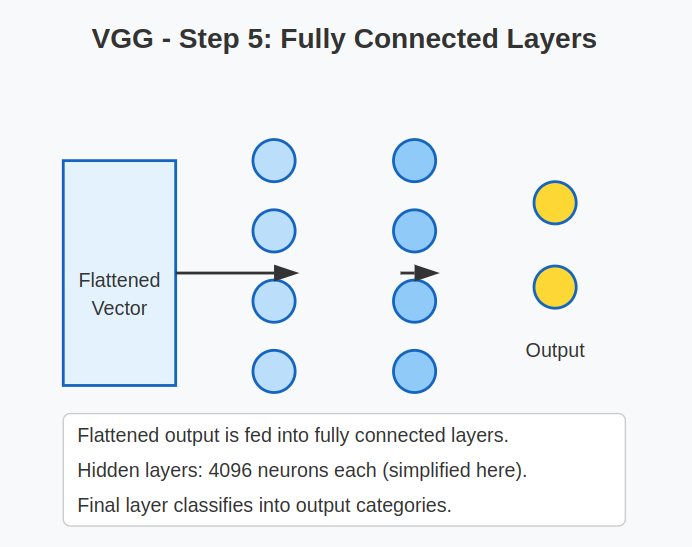
- After the convolution and pooling operations, the output is flattened right into a 1D vector.
- VGG usually makes use of two or three absolutely linked layers:
- First two FC layers: 4096 neurons every
- Last FC layer: Variety of neurons equal to the variety of output lessons (e.g., 1000 for ImageNet).
These layers function a classifier on prime of the extracted options.
6. Output Layer:
- The ultimate layer makes use of the Softmax activation perform to output chances for every class.
- Instance:
- For ImageNet, it predicts over 1,000 totally different object classes.
7. Parameter Counts:
One of many main traits of VGG is its giant variety of parameters, particularly because of the absolutely linked layers.
| Mannequin | Complete Parameters | Layers |
| VGG16 | ~138 million | 16 |
| VGG19 | ~143 million | 19 |
This makes VGG computationally costly but in addition extremely able to studying wealthy characteristic representations.
VGG16 Structure Breakdown (Instance):
| Layer Sort | Output Measurement | Filters/Neurons |
| Enter | (224, 224, 3) | – |
| Conv3-64 x2 | (224, 224, 64) | 64 |
| Max Pool | (112, 112, 64) | – |
| Conv3-128 x2 | (112, 112, 128) | 128 |
| Max Pool | (56, 56, 128) | – |
| Conv3-256 x3 | (56, 56, 256) | 256 |
| Max Pool | (28, 28, 256) | – |
| Conv3-512 x3 | (28, 28, 512) | 512 |
| Max Pool | (14, 14, 512) | – |
| Conv3-512 x3 | (14, 14, 512) | 512 |
| Max Pool | (7, 7, 512) | – |
| Flatten | (25088 | – |
| Totally Linked | (4096) | 4096 |
| Totally Linked | (4096) | 4096 |
| Totally Linked | (1000) | 1000 |
| Softmax Output | (1000) | – |
Why is VGG Structure Particular?
- Modularity: It repeats the identical block construction, making it simple to scale and modify.
- Function Hierarchy: Decrease layers be taught easy options (edges, colours), whereas deeper layers be taught complicated patterns (shapes, objects).
- Transferability: The options discovered by VGG work properly on totally different datasets, which is why pre-trained VGG fashions are closely utilized in switch studying.
Benefits of VGG
- Simplicity: VGG’s uniform structure (stacked 3×3 filters) makes it simpler to know and implement.
- Switch Studying Pleasant: Pre-trained VGG fashions are extensively used for switch studying, saving time and sources on new initiatives.
- Robust Baseline: Regardless of being older, VGG serves as a sturdy baseline in lots of analysis experiments and purposes.
- Constant Efficiency: VGG performs reliably on a variety of visible duties past picture classification.
Disadvantages of VGG
- Giant Mannequin Measurement: VGG requires vital storage (over 500MB), making it much less sensible for deployment on cell or edge gadgets.
- Computationally Heavy: The mannequin has excessive reminiscence utilization and gradual inference instances on account of its depth and variety of parameters.
- Outperformed by Trendy Architectures: Fashions like ResNet and MobileNet obtain related or higher accuracy with fewer parameters and quicker processing.
Get accustomed to well-liked Machine Studying algorithms.
Actual-World Functions of VGG
| Discipline | Software Instance |
| Healthcare | Medical picture evaluation and diagnostics |
| Automotive | Object recognition in autonomous autos |
| Safety | Face detection and surveillance methods |
| Retail | Visible product search and advice |
| Artwork & Design | Model switch and picture enhancement |
In style VGG-Primarily based Tasks
- Picture Model Switch – Utilizing VGG layers to mix the fashion of 1 picture with the content material of one other.
- Function Extraction – Leveraging VGG as a characteristic extractor in complicated pipelines.
- Object Detection – Mixed with area proposal networks in duties like Sooner R-CNN.
Uncover how a Recurrent Neural Community (RNN) works and why it’s extensively used for language modeling and time-series predictions.
Conclusion
The VGG structure is a basic a part of deep studying historical past. VGG, with its refined simplicity and demonstrated effectiveness, is essential data for anybody exploring pc imaginative and prescient.
Whether or not you’re growing a analysis challenge, using switch studying, or attempting out fashion switch, VGG gives a sturdy base to start.
Construct a Profession in Machine Studying
Our Information Science and Machine Studying program teaches you core neural community strategies that energy pc imaginative and prescient.
Study from MIT school via hands-on initiatives and customized mentorship to construct sensible, data-driven options. Enroll now to raise your profession in AI and real-world innovation.
Regularly Requested Questions
1. Why are 3×3 filters utilized in VGG?
VGG makes use of 3×3 filters as a result of they seize small particulars whereas permitting deeper networks with fewer parameters in comparison with bigger filters like 5×5 or 7×7.
2. How does VGG examine to ResNet?
VGG is easier however heavier. ResNet makes use of residual connections to coach deeper networks with higher efficiency and effectivity.
3. Can VGG be used for non-image knowledge?
VGG is optimized for photographs, however its convolutional ideas can generally be tailored to sequential knowledge like audio or video.
4. How do VGG16 and VGG19 differ?
The principle distinction lies in depth—VGG19 has three extra convolutional layers than VGG16, which barely improves accuracy however will increase computation.
5. Is VGG nonetheless related as we speak?
Sure, particularly in training, analysis baselines, and switch studying, although trendy architectures could outperform it in manufacturing environments.